If you remove the first word from the string "hello world", what should the result be? This is the story of how we discovered that the answer could be your root password!
Introduction
All x86-64 CPUs have a set of 128-bit vector registers called the XMM registers. You can never have enough bits, so recent CPUs have extended the width of those registers up to 256-bit and even 512-bits.
The 256-bit extended registers are called YMM, and the 512-bit registers are ZMM.
These big registers are useful in lots of situations, not just number crunching! They’re even used by standard C library functions, like strcmp, memcpy, strlen and so on.
Let’s take a look at an example. Here are the first few instructions of glibc’s AVX2 optimized strlen:
Now we have the position of the first nul byte, in just four machine instructions!
You can probably imagine just how often strlen is running on your system right now, but suffice to say, bits and bytes are flowing into these vector registers from all over your system constantly.
Zeroing Registers
You might have noticed that I missed one instruction, and that’s vzeroupper.
You guessed it, vzeroupper will zero the upper bits of the vector registers.
The reason we do this is because if you mix XMM and YMM registers, the XMM registers automatically get promoted to full width. It’s a bit like integer promotion in C.
This works fine, but superscalar processors need to track dependencies so that they know which operations can be parallelized. This promotion adds a dependency on those upper bits, and that causes unnecessary stalls while the processor waits for results it didn’t really need.
These stalls are what glibc is trying to avoid with vzeroupper. Now any future results won’t depend on what those bits are, so we safely avoid that bottleneck!
The Vector Register File
Now that we know whatvzeroupper does, how does it do it?
Your processor doesn’t have a single physical location where each register lives, it has what’s called a Register File and a Register Allocation Table. This is a bit like managing the heap with malloc and free, if you think of each register as a pointer. The RAT keeps track of what space in the register file is assigned to which register.
In fact, when you zero an XMM register, the processor doesn’t store those bits anywhere at all - it just sets a flag called the z-bit in the RAT. This flag can be applied to the upper and lower parts of YMM registers independently, so vzeroupper can simply set the z-bit and then release any resources assigned to it in the register file.
A register allocation table (left) and a physical register file (right).
Speculation
Hold on, there’s another complication! Modern processors use speculative execution, so sometimes operations have to be rolled back.
What should happen if the processor speculatively executed a vzeroupper, but then discovers that there was a branch misprediction? Well, we will have to revert that operation and put things back the way they were… maybe we can just unset that z-bit?
If we return to the analogy of malloc and free, you can see that it can’t be that simple - that would be like calling free() on a pointer, and then changing your mind!
That would be a use-after-free vulnerability, but there is no such thing as a use-after-free in a CPU… or is there?
Spoiler: yes there is 🙂
This animation shows why resetting the z-bit is not sufficient.
Vulnerability
It turns out that with precise scheduling, you can cause some processors to recover from a mispredicted vzeroupper incorrectly!
This technique is CVE-2023-20593 and it works on all Zen 2 class processors, which includes at least the following products:
AMD Ryzen 3000 Series Processors
AMD Ryzen PRO 3000 Series Processors
AMD Ryzen Threadripper 3000 Series Processors
AMD Ryzen 4000 Series Processors with Radeon Graphics
AMD Ryzen PRO 4000 Series Processors
AMD Ryzen 5000 Series Processors with Radeon Graphics
AMD Ryzen 7020 Series Processors with Radeon Graphics
AMD EPYC “Rome” Processors
The bug works like this, first of all you need to trigger something called the XMM Register Merge Optimization2, followed by a register rename and a mispredicted vzeroupper. This all has to happen within a precise window to work.
We now know that basic operations like strlen, memcpy and strcmp will use the vector registers - so we can effectively spy on those operations happening anywhere on the system! It doesn’t matter if they’re happening in other virtual machines, sandboxes, containers, processes, whatever!
This works because the register file is shared by everything on the same physical core. In fact, two hyperthreads even share the same physical register file.
Don’t believe me? Let’s write an exploit 🙂
Exploitation
There are quite a few ways to trigger this, but let’s examine a very simple example.
Here cvtsi2sd is used to trigger the merge optimization. It’s not important what cvtsi2sd is supposed to do, I’m just using it because it’s one of the instructions the manual says use that optimization3.
Then we need to trigger a register rename, vmovdqa will work. If the conditional branch4 is taken but the CPU predicts the not-taken path, the vzeroupper will be mispredicted and the bug occurs!
Optimization
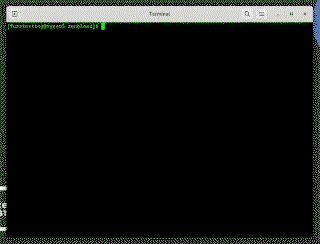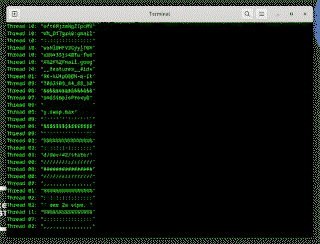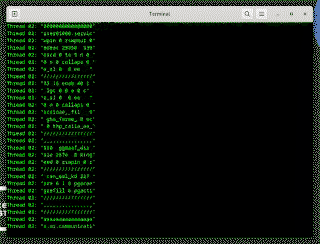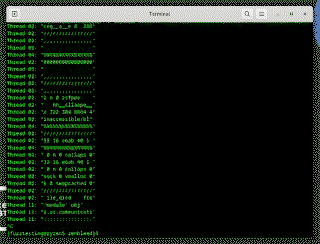
Exploit Running
It turns out that mispredicting on purpose is difficult to optimize! It took a bit of work, but I found a variant that can leak about 30 kb per core, per second.
This is fast enough to monitor encryption keys and passwords as users login!
We’re releasing our full technical advisory, along with all the associated code today. Full details will be available in our security research repository.
If you want to test the exploit, the code is available here.
Note that the code is for Linux, but the bug is not dependent on any particular operating system - all operating systems are affected!
Discovery
I found this bug by fuzzing, big surprise 🙂 I’m not the first person to apply fuzzing techniques to finding hardware flaws. In fact, vendors fuzz their own products extensively - the industry term for it is Post-Silicon Validation.
So how come this bug wasn’t found earlier? I think I did a couple of things differently, perhaps with a new perspective as I don’t have an EE background!
Feedback
The best performing fuzzers are guided by coverage feedback. The problem is that there is nothing really analogous to code coverage in CPUs… However, we do have performance counters!
Feeding this data to the fuzzer lets us gently guide it towards exploring interesting features that we wouldn’t have been able to find by chance alone!
It was challenging to get the details right, but I used this to teach my fuzzer to find interesting instruction sequences. This allowed me to discover features like merge optimization automatically, without any input from me!
Oracle
When we fuzz software, we’re usually looking for crashes. Software isn’t supposed to crash, so we know something must have gone wrong if it does.
How can we know if a a CPU is executing a randomly generated program correctly? It might be completely correct for it to crash!
Well, a few solutions have been proposed to this problem. One approach is called reversi. The general idea is that for every random instruction you generate, you also generate the inverse (e.g. ADD r1, r2 → SUB r1, r2). Any deviation from the initial state at the end of execution must have been an error, neat!
The reversi approach is clever, but it makes generating testcases very complicated for a CISC architecture like x86.
A simpler solution is to use an oracle. An oracle is just another CPU or a simulator that we can use to check the result. If we compare the results from our test CPU to our oracle CPU, any mismatch would suggest that something went wrong.
I developed a new approach with a combination of these two ideas, I call it Oracle Serialization.
Oracle Serialization
As developers we monitor the macro-architectural state, that’s just things like register values. There is also the micro-architectural state which is mostly invisible to us, like the branch predictor, out-of-order execution state and the instruction pipeline.
Serialization lets us have some control over that, by instructing the CPU to reset instruction-level parallelism. This includes things like store/load barriers, speculation fences, cache line flushes, and so on.
The idea of a Serialized Oracle is to generate a random program, then automatically transform it into a serialized form.
A randomly generated sequence of instructions, and the same sequence but with randomized alignment, serialization and speculation fences added.
movnti [rbp+0x0],ebx
movnti [rbp+0x0],ebx
sfence
rcr dh,1
rcr dh,1
lfence
sub r10, rax
sub r10, rax
mfence
rol rbx, cl
rol rbx, cl
nop
xor edi,[rbp-0x57]
xor edi,[rbp-0x57]
These two program might have very different performance characteristics, but they should produce identical output. The serialized form can now be my oracle!
If the final states don’t match, then there must have been some error in how they were executed micro-architecturally - that could indicate a bug.
This is exactly how we first discovered this vulnerability, the output of the serialized oracle didn’t match!
Solution
We reported this vulnerability to AMD on the 15th May 2023.
AMD have released an microcode update for affected processors. Your BIOS or Operating System vendor may already have an update available that includes it.
Workaround
It is highly recommended to use the microcode update.
If you can’t apply the update for some reason, there is a software workaround: you can set the chicken bitDE_CFG[9].
This may have some performance cost.
Linux
You can use msr-tools to set the chicken bit on all cores, like this:
# wrmsr -a 0xc0011029 $(($(rdmsr -c 0xc0011029) | (1<<9)))
FreeBSD
On FreeBSD you would use cpucontrol(8).
Others
If you’re using some other operating system and don’t know how to set MSRs, ask your vendor for assistance.
Note that it is not sufficient to disable SMT.
Detection
I am not aware of any reliable techniques to detect exploitation. This is because no special system calls or privileges are required.
It is definitely not possible to detect improper usage of vzeroupper statically, please don’t try!
Conclusion
It turns out that memory management is hard, even in silicon 🙂
Acknowledgements
This bug was discovered by me, Tavis Ormandy from Google Information Security!
I couldn’t have found it without help from my colleagues, in particular Eduardo Vela Nava and Alexandra Sandulescu. I also had help analyzing the bug from Josh Eads.
You don’t need to set ymm0 explicitly, all VEX encoded instructions that write to xmm automatically zero the upper part.↩︎
See Software Optimization Guide for AMD EPYC™ 7003 Processors, section 2.11.5.↩︎
See Software Optimization Guide for AMD EPYC™ 7003 Processors, section 2.11.5.↩︎
In fact, conditional branches are not necessary at all because of SLS.↩︎